Memory Fabric System Tackles AI Inference’s Memory Bandwidth Challenges
Enfabrica's new EMFASYS system integrates CXL-based DDR5 memory with RDMA Ethernet to reduce inference costs for large-scale AI workloads through an elastic memory fabric.
The exponential growth of generative AI and large language models (LLMs) has created a significant bottleneck in data centers: the I/O and memory subsystem. As AI workloads become more complex and data-intensive, the existing architecture of tightly-coupled GPUs and high-bandwidth memory (HBM) is proving inefficient for scaling. In response to this challenge, Enfabrica Corporation has announced the availability of its Elastic Memory Fabric System (EMFASYS), a new hardware and software solution designed to decouple memory from compute resources and enable a more efficient, rack-scale approach to AI infrastructure.
Merging Available Technologies to Support AI Demands
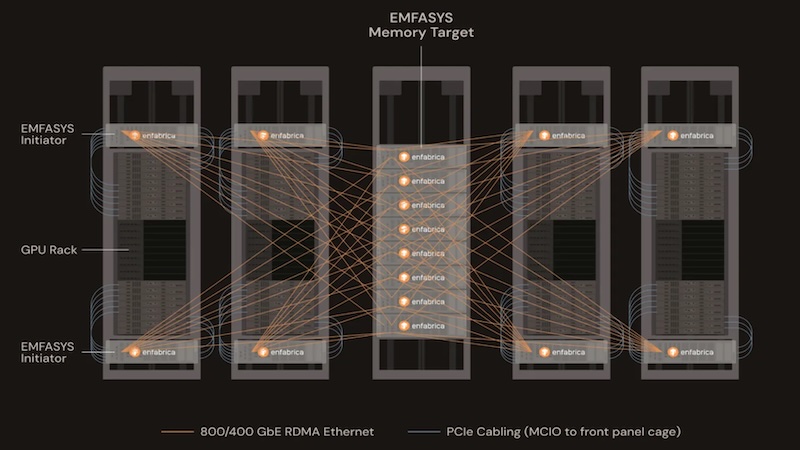
The core of the EMFASYS system is a novel integration of two key technologies: Compute Express Link (CXL) and Remote Direct Memory Access (RDMA) over Ethernet. CXL is an open standard interconnect that allows for high-speed, low-latency communication between a CPU and devices like memory expansion modules, while RDMA over Ethernet enables a server to directly access memory on another server without involving the remote host’s CPU. By combining these two technologies with its proprietary Accelerated Compute Fabric SuperNIC (ACF-S) silicon, Enfabrica has created a standalone memory appliance that can be accessed by any GPU server within a network.
EMFASYS delivers resource utilization improvements through an elastic memory fabric with a significant reduction in cost per token per user. Image used courtesy of Enfabrica
This architectural shift is a significant departure from traditional designs, where memory is confined to the individual GPU servers. The EMFASYS appliance, powered by Enfabrica’s 3.2 Terabits/second ACF-S chip, can connect up to 144 CXL memory lanes to 400/800 Gigabit Ethernet (GbE) ports. This provides a shared memory target of up to 18 Terabytes of CXL DDR5 DRAM per node, accessible over a low-latency RDMA over Ethernet connection. The result is an elastic memory fabric that allows AI cloud operators to scale memory capacity independently of GPU count. This is a critical advantage for workloads that are memory-bound, not compute-bound, such as large-context LLM inference.
By offloading the memory burden from the GPU’s expensive and limited HBM to more plentiful and cost-effective commodity DDR5 DRAM, EMFASYS aims to improve the utilization of GPU and HBM resources. The system’s software stack, which is based on Infiniband Verbs, manages a caching hierarchy that hides transfer latency, ensuring uncompromised AI workload performance with microsecond read access times. This tiered memory approach allows for more efficient use of resources, as the most frequently accessed data can reside in the fast HBM, while larger datasets are stored in the CXL-based DDR5 memory.

Using commonly available technologies, such as CXL DDR5 DRAM, allows EMFASYS to be more easily implemented than competing solutions. Image used courtesy of Adobe Stock
Cost Efficiency and System Flexibility
The benefits of this architecture are particularly evident in the economics of large-scale AI inference. As AI models and their context windows grow, the memory requirements per query are increasing dramatically. Enfabrica claims that EMFASYS can reduce the cost per token per user by up to 50%, enabling foundational LLM providers to offer more cost-effective services. This is achieved by containing the linear growth of GPU HBM and CPU DRAM within the AI server, and instead leveraging a more scalable, shared memory pool.
Enfabrica’s ACF-S chip, the heart of the EMFASYS system, is also notable for its flexibility. In addition to its role in the memory fabric system, the chip acts as a multi-port 800 GbE NIC for GPU servers, providing high-throughput, zero-copy data placement and steering. The chip’s architecture supports both scale-up and scale-out interfaces, making it a versatile tool for building large, interconnected AI clusters.
Summary
The release of EMFASYS builds on Enfabrica’s earlier success in sampling the ACF-S chip. By creating an elastic, rack-scale memory fabric, Enfabrica is tackling a fundamental bottleneck in the scaling of AI infrastructure. The EMFASYS solution presents a compelling alternative to traditional scaling methods, promising to enhance GPU utilization, reduce operational costs, and accelerate the development of next-generation AI workloads.


