TinyM2Net is An ML Algorithm for Resource-Constrained Devices
TinyM2Net is a multimodal learning framework, designed to work with resource-constrained tiny devices like microprocessors and microcontrollers. When tested with COVID-19 audio detection and battlefield object detection, It outperformed similar recognition tools and worked well on a Raspberry Pi 4.
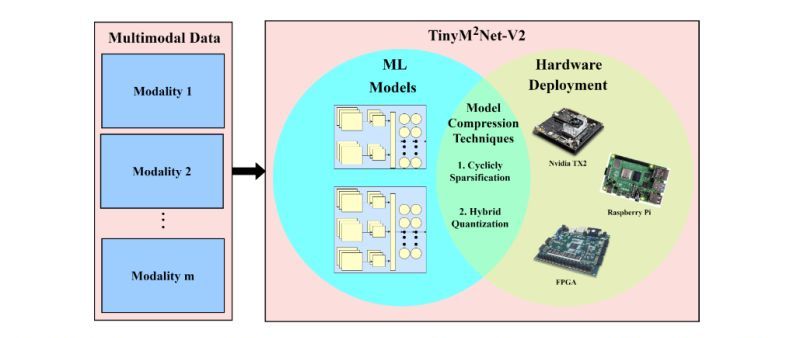
TinyM2Net is a multimodal learning framework, designed to work with resource-constrained tiny devices like microprocessors and microcontrollers. When tested with COVID-19 audio detection and battlefield object detection, It outperformed similar recognition tools and worked well on a Raspberry Pi 4.
IoT devices are everywhere, from your smartphone smartwatch to your fridge washing macing and AC, and nowadays those are using Artificial Intelligence (AI) and Machine Learning(ML) to work better and brighter for the end users. However, running ML algorithms on resource-constrained microcontrollers and microprocessors is challenging! That is why the researchers are employing multimodality to train machine learning models. One such tool is the TinyM2Net.
In simpler terms, modality refers to how something is experienced or how we sense things, like speech, sight, or sound. Now, a multimodal machine-learning algorithm can process and relate information from multiple modalities, from medical diagnosis, security, and combat fields to robotics, vision analytics, knowledge reasoning, or navigation.
When running machine learning on tiny, resource-constrained devices, it becomes quite challenging. A typical MCU has an SRAM of less than 512kB, which makes it hard to run complex programs like deep learning on these devices. One easy solution to this problem is to process the data directly on these devices, which requires efficient multimodal learning inference with a low peak memory consumption. So researchers from the University of Maryland and the U.S. Army have introduced a new multimodal learning framework designed specifically for these resource-constrained tiny edge devices.
TinyM2Net Multimodal Learning Framework
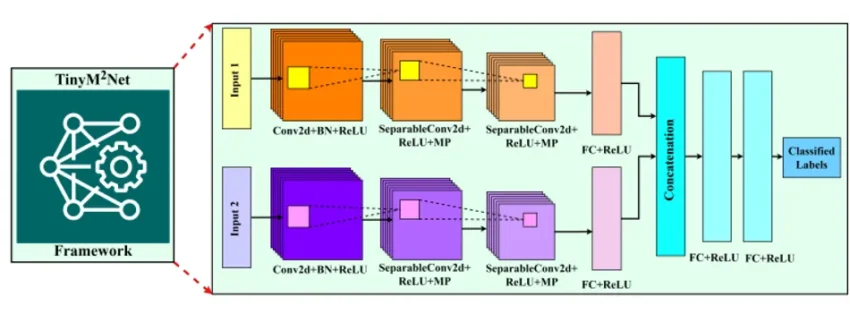
The TinyM2Net is built upon a convolutional neural network (CNN), which had previously shown promise in classifying both audio and image data. However, traditional CNN models are very bulky and require a lot of resources to operate properly. So researchers have used various compression techniques to optimize the network architecture and as a result, the TinyM2Net was born.
In the paper “TinyM2Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices ” researchers have mentioned how they used “DS-CNN” to process multimodal input like images and audio without sacrificing accuracy. The framework also uses low-precision and mixed-precision model quantization. This reduces accuracy but to compensate for that the team chose two different bit precision settings, INT4 and INT8 for the TinyM2Net framework.
Evaluating Covid & Battlefield Detection from Multimodal Data
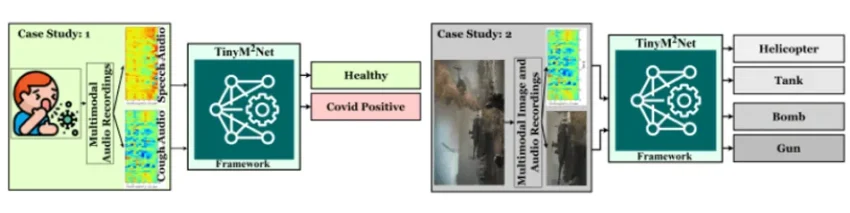
Researchers tested the TinyM2Net framework on two different scenarios first is COVID-19 Detection using Sound and battlefield Object Detection using Sound and Images,
The COVID-19 detection model had 929 cough recordings and 893 speech recordings, and it was 90.4% accurate in identifying COVID-19 when using a standard measurement. When they tried simpler measurements, accuracy slightly dropped to 89.6% and 83.6%. However, by implementing their unique technique, they managed to raise the accuracy back to 88.4%. For comparison, the best other models that only used one type of sound (either cough or speech) were about 73% accurate.
Next, the research team wanted to detect battlefield items like helicopters, bombs, guns, and tanks using the model, so in an endeavor, they gathered 2745 images and sounds for these objects. Their model was 98.5% accurate using a standard measurement. Using simpler measurements, accuracy was 97.9% and 88.7%. In this scenario, their unique approach managed to achieve an accuracy of 97.5%. When using just one type of input (either image or sound), the accuracy was 93.6%.
The team used the TinyM2Net framework on small devices like the Raspberry Pi 4 with 2GB memory. More details are available in the research work published on Cornell University’s research-sharing platform, arXiv under open-access terms.


