Hiddenite, AI Processor for Reduced Computational Power Consumption
AI accelerators are specialized hardware designs that are built for computing complex AI workloads in the field of edge computing. While deep neural networks are assumed to be the optimized solution for image recognition and object detection, AI tasks, a group of researchers from the Tokyo Institute of Technology in Japan, proposed a hardware accelerator chip design, Hiddenite, to achieve high accuracy for the calculation of sparse hidden neural networks.

AI accelerators are specialized hardware designs that are built for computing complex AI workloads in the field of edge computing. While deep neural networks are assumed to be the optimized solution for image recognition and object detection, AI tasks, a group of researchers from the Tokyo Institute of Technology in Japan, proposed a hardware accelerator chip design, Hiddenite, to achieve high accuracy for the calculation of sparse hidden neural networks.
Hiddenite combines weight generation and super mask expansion to significantly reduce external memory access for improved computation efficiency. The super mask is defined by the top-k% highest scores, denotes the unselected and selected connections as 0 and 1, respectively. The hidden neural network helps reduce computational efficiency from the software side.
“Reducing external memory access is key to reducing power consumption. Currently, achieving high inference accuracy requires large models. However, this increases external memory access to load model parameters. Our main motivation behind the development of Hiddenite was to reduce this external memory access,” explains Prof. Motomura.
Hiddenite stands for Hidden Neural Network Inference Tensor Engine (Hiddenite) is the first HNN inference chip to offer benefits in reducing external memory access and increasing energy efficiency. On-chip weight generation is capable of re-generating weight using a random number generator to eliminate the requirement to access and store weights in external memory. The provision of “on-chip supermask expansion,” will considerably decrease the number of supermasks that must be loaded by the accelerator. The Hiddenite chip’s high-density four-dimensional (4D) parallel processor maximizes data re-use during the computational process and thereby improves efficiency.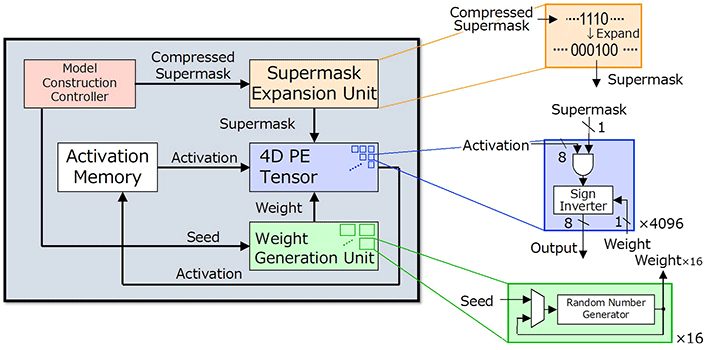
“The first two factors are what set the Hiddenite chip apart from existing DNN inference accelerators,” reveals Prof. Motomura. “Moreover, we also introduced a new training method for hidden neural networks, called ‘score distillation,’ in which the conventional knowledge distillation weights are distilled into the scores because hidden neural networks never update the weights. Accuracy using score distillation is comparable to the binary model while being half the size of the binary model.”
The team used the Taiwan Semiconductor Manufacturing Company’s (TSMC) 40 nm technology to fabricate the prototype chip. With size at 3×3 mm, the chip is capable of doing 4,096 MAC (multiply-and-accumulate) operations simultaneously with the computational efficiency of up to 34.8 tera operations per second (TOPS) per watt of power while reducing the amount of model transfer to half that of binarized networks.
The research article was presented in the International Solid-State Circuits Conference 2022 under the title “Hiddenite: 4K-PE Hidden Network Inference 4D-Tensor Engine Exploiting On-Chip Model Construction Achieving 34.8-to-16.0TOPS/W for CIFAR-100 and ImageNet.”

