A novel approach for in-pixel processing for resource-constrained edge AI applications
Computer vision applications that range from object detection and pattern recognition to computational healthcare and security surveillance systems take the input image for further processing, which in traditional hardware implementation has a vision sensing and vision processing platform as a separate entity within the AI system. The segregation of CMOS-based vision sensor platforms and vision computing platform have raised concerns regarding throughput, bandwidth and energy efficiency.
Computer vision applications that range from object detection and pattern recognition to computational healthcare and security surveillance systems take the input image for further processing, which in traditional hardware implementation has a vision sensing and vision processing platform as a separate entity within the AI system. The segregation of CMOS-based vision sensor platforms and vision computing platform have raised concerns regarding throughput, bandwidth and energy efficiency. To mitigate these challenges, existing research work shows the design approach to bring visual data processing closer to the source, which means closer to the CMOS image sensors through three techniques of near-sensor processing, in-sensor processing and in-pixel processing.
In the proposed near-sensor processing technique, the ML accelerator on the same PCB as the CMOS image sensor chip brings the computation closer to the source but suffers data transfer costs between the processing chip and image sensor. While in-sensor processing solves this bottleneck, they still require data to be real in parallel through communication buses from image sensor photo-diode arrays into peripheral processing circuits. The third approach of in-pixel processing has aimed to embed all the processing capabilities in the image sensor pixels.
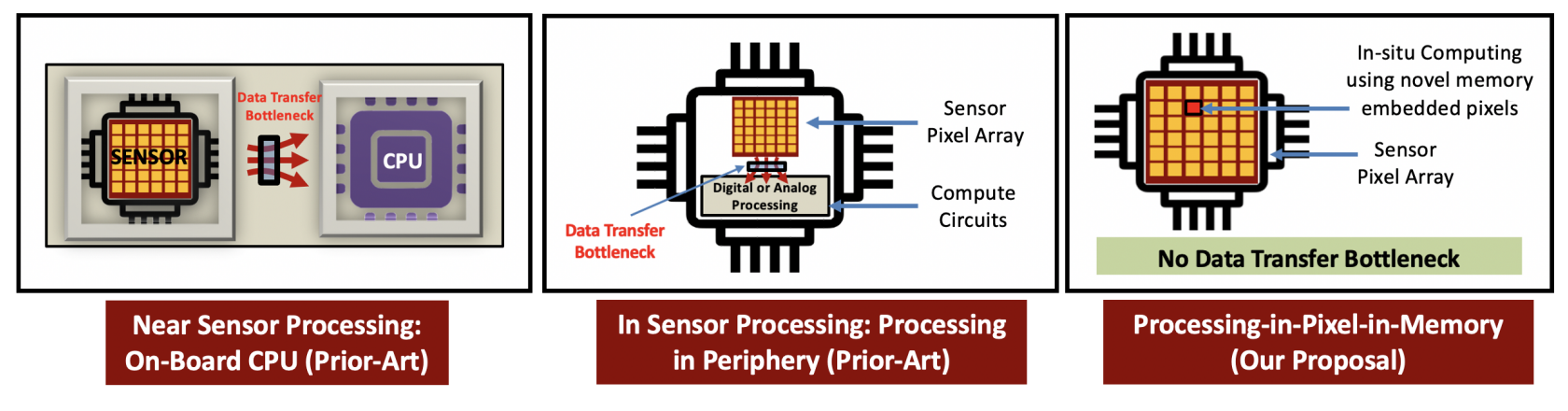
The initial work carried out on in-pixel processing focused on in-pixel analog convolution that required the use of non-volatile memories. This fails to support multi-bit, multi-channel convolution operations required by advanced deep learning applications. As in-pixel processing is relevant to the research paper titled, “P2M: A Processing-in-Pixel-in-Memory Paradigm for Resource-Constrained TinyML Applications” that proposes a novel processing in-pixel-in-memory (P2M) model wherein the memory-embedded pixels will be capable of carrying out massively parallel dot product accelerations using photodiode current as input activation and weights calculations within individual pixels.
Processing-in-Pixel-in-Memory Paradigm
A team of researchers affiliated with the Department of Electrical and Computer Engineering and the Information Sciences Institute at the University of Southern California, United States continued the work to develop a compact MobileNet-V2-based model for P2M hardware implementation on visual wake words dataset (VWW) achieving a reduction of data transfer bandwidth from the sensor to ADCs by up to 21x compared to the standard near-sensor and in-sensor processing implementations.
The proposed circuit model has three phases of operation: Reset phase, multi-pixel convolution phase, and ReLU operation. In the first reset phase, the voltage on the photodiode node M is precharged or reset by activating the reset transistor Gr. Next, in the multi-pixel convolution phase, the discharge of reset transistor Gr takes place which deactivates the Gr. Using the select control lines, the gate of the GH transistor is pulled high to VDD to activate the XxYx3 multi-pixels.
“As the photodiode is sensitive to the incident light, photo-current is generated as light shines upon the diode (for a duration equal to exposure time), and voltage on the gate of Gs is modulated in accordance to the photodiode current that is proportional to the intensity of incident light,” the team explains. “The pixel output voltage is a function of the incident light (voltage on node M) and the driving strength of the activated weight transistor within each pixel.”
The pixel output from multiple pixels is taken from the column lines and represented in the multi-pixel analog convolution output. This analog output is converted to digital value through SS-ADC in the periphery circuit and the whole operation is repeated twice for positive and negative weights. Finally, in the ReLU operation, the output of the counter is latched and represents a quantized ReLU output. The entire P2M circuit was simulated using commercial 22nm GlobalFoundry FD-SOI process technology.
Will Processing-in-Pixel-in-Memory be the future?
When most of the low power edge IoT devices have limited on-memory of a few kilo-bytes, the team has implemented a P2M approach on these devices for TinyML applications. Utilizing Visual Wake Words (VWW) dataset comes with high-resolution images that include visual cues to wake up AI-powered home assistant devices requiring real0time interference in a resource-constrained environment. The constraints are defined as the detection of the presence of a human in the image frame with peak RAM close to 250kB for which the input image undergoes downsampling to obtain a 224×224 resolution image. The chosen CNN architecture, MobileNetV2 has 32 and 320 channels for the first and last convolutional layers respectively that support a full resolution of 560×560 pixels. “In order to avoid overfitting to only two classes in the VWW dataset, we decrease the number of channels in the last depthwise separable convolutional block by 3×,” as the team reports.
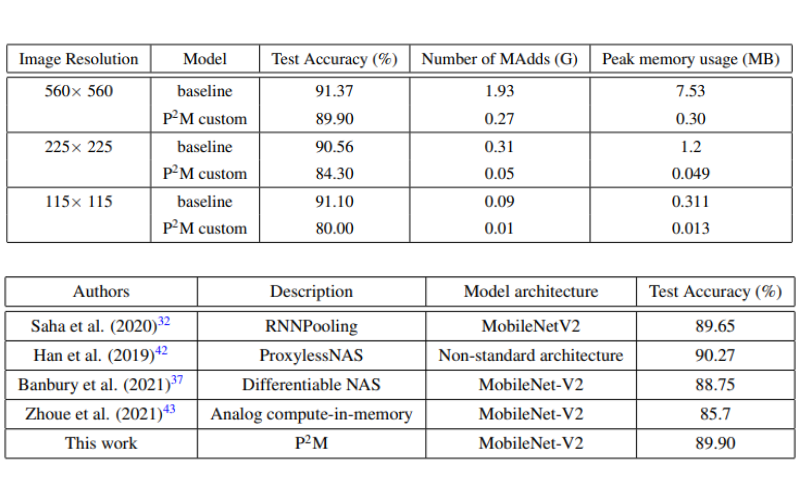
The entire experimentation of training the baseline and P2M models in PyTorch using an SGC optimizer with 0.9 momentum for 100 epochs is performed on an NVIDIA 2080Ti GPU with 11GB memory. According to the results, as the image resolution increases from 115×115 to 225×225 and then 560×560 pixels, the test accuracy for the custom P2M models improves from 80.00% to 84.30% and then 89.90% respectively. Also, the performance comparison of the proposed P2M models with state-of-the-art deep convolutional neural networks on the VWW dataset shows the method to outperform most of the proposed ideas and is close to the one proposed by Saha et. al. [2].
The research work was published on Cornell University’s research sharing platform, arXiv under open access terms.
References
- Gourav Datta, Souvik Kundu, Zihan Yin, Ravi Teja Lakkireddy, Joe Mathai, Ajey Jacob, Peter A. Beerel, Akhilesh R. Jaiswal: P2M: A Processing-in-Pixel-in-Memory Paradigm for Resource-Constrained TinyML Applications. DOI arXiv: 2203.04737 [cs.LG].
- Saha, O., Kusupati, A., Simhadri, H. V., Varma, M. & Jain, P. RNNPool: Efficient non-linear pooling for RAM constrained inference. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F. & Lin, H. (eds.) Advances in Neural Information Processing Systems, vol. 33, 20473–20484 (Curran Associates, Inc., 2020).


